Redes neuronales convolucionales: FaceSwap Original
En este blog hablaré de mi experiencia adaptando, modificando y consiguiendo los recursos necesarios para realizar un faceswap.
| Víctor | El tuercas | Víctor tuerqueado |
|---|---|---|
 |
 |
 |
Primero lo primero: ¿DeepFakes? ¿FaceSwap?
DeepFakes fue (porque lo banearon) un subreddit /r/deepfakes. En este subreddit, un héroe anónimo compartió la infraestrctura necesaria a partir de una arquitectura propia de una red neuronal convolucional para que la cara de alguien pueda estar en alguna imagen donde aparezca alguien más, pasando prácticamente desapercibida, a esto se le llama FaceSwap. En el Manifesto de deepfakes en GitHub podrás leer más al respecto.
Arquitectura de la red.
A diferencia de otros modelos de redes neuronales, como las VGG, AlexNet, etc, el modelo original de DeepFakes es difícil de encontrar. Tal vez por toda la censura que recibió, la mala fama del proyecto, las cosas que desencadenó, tanto así que el autor aún se desconoce, pero no hay mucha difusión acerca de la arquitectura original de deepfakes. Tampoco se sabe en qué paper se basó el autor, sin embargo, en su código hace referencia a otros repositorios de GitHub. Antes de entrar al repositorio de GitHub, debes saber que no solamente hay un modelo de deepfakes. En el repositorio hay muchos otros como:
y además, claro el original. En este blog todos los entrenamientos, conversiones, extracciones y referencias serán en relación al modelo deepfakes original.
Autoencoders
Las redes neuronales autoencoders son un tipo de red neuronal profunda en el cual el número de neuronas de la capa de entrada es el mismo que el número de neuronas de la capa de salida. El propósito de las autoencoders es reconstruir los datos de entrada (minimizando la diferencia entre la entrada y la salida). Por esto, las autoencoders son redes neuronales no supervisadas.
En general, la arquitectura utilizada por deepfakes es la de una red AutoEncoder y no una convolucional como tradicionalmente se tratan todos los problemas de procesamiento de imágenes en la actualidad. Para conocer más acerca de las ANN, puedes ver:
En general, las AutoEncoders constan de dos redes neuronales profundas: una Encoder y otra Decoder: la encoder trata de encontrar $h = f(x)$ mientras que la decoder trata de reconstruir $ r = g(h) $. Sin embargo, si una autoencoder encuentra exactamente g(f(x)) = x , entonces fallamos miserablemente. En las aplicaciones, hay muchas cosas que se le pueden agregar a los datos para evitar que aprenda perfectamente. Se ve claramente como el sobre-aprendizaje es un problema más serio en las ANN.
¿Cuál es el problema de las ANN para hacer Faceswap? Si entrenamos dos autoencoders de manera separada, serán incompatibles entre ellas. Si entrenamos dos autoencoders de manera separada con caras diferentes, lo que codifique una serán características diferentes de la otra. ¿Qué hizo deepfakes? Entrenó con un autoencoder, y en este autoencoder, usó solamente un encoder y dos decoders (uno por cada persona). Es decir, mientras un decodificador aprende con la cara de Alicia, el otro decodificador aprende la cara de Bob, mientras que el codificador tiene que encontrar características de ambas.
Aquí dejo una imagen muy representativa de deepfakes, que la conseguí en el último de los enlaces que anexé anteriormente:
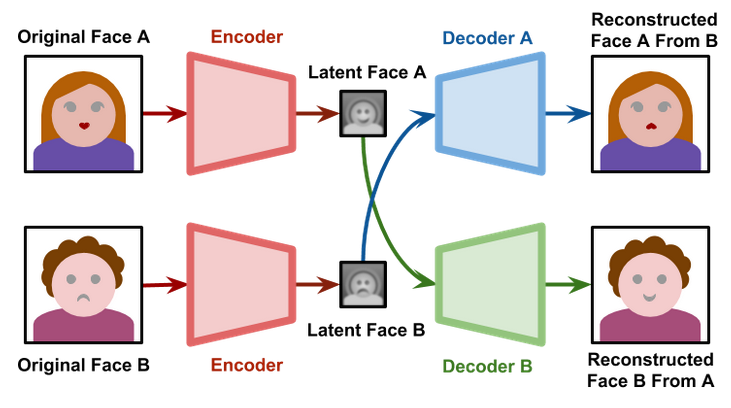
El modelo original
Como ya he mencionado, es difícil conseguir alguna imagen de la arquitectura de deepfakes en internet. Sin embargo, mientras hago la imagen, aquí dejo el modelo original que encontré a partir de leer todo el código del repositorio:
Arquitectura de la red neuronal del encoder:
- Capa de entrada: 64 x 64 x 3
- Capa convolucional: Filtro de tamaño 128
- Capa convolucional: Filtro de tamaño 256
- Capa convolucional: Filtro de tamaño 512
- Capa convolucional: Filtro de tamaño 1024
- Capa densa (fully connected; flatten): 1024
- Capa densa (fully connected): 4 x 4 x 2014
- Reshape: 4 x 4 x 1024
- Capa de upscale: Filtro de tamaño 512
- Capa de salida: 8 x 8 x 512
Arquitectura de la red neuronal del decoder:
- Capa de entrada: 8 x 8 x 512 (es la salida del encoder)
- Capa de upscale: Filtro de 256
- Capa de upscale: Filtro de 128
- Capa de upscale: Filtro de 64
- Capa convolucional: Filtro de tamaño 3
- Capa de upscale: Filtro de 128
- Capa de upscale: Filtro de 64
- Capa de upscale: Filtro ed 64
- Capa convolucional: Filtro de tamaño 1
- Capa de salida: 64 x 64 x 3
También cabe aclarar que todos los kernels son de tamaño 5 x 5, y el padding que se utilizó fue el “same” de keras (es decir, stride=1 o half-padding).
Aquí agrego dos imágenes de una red neuronal AutoEncoder para faceswap basada en deepfakes. Como se podrá ver, es muy parecida. Lo que cambió principalmente fue que agregó capas de atención al modelo, y agregó otra capa densa a la red encoder.
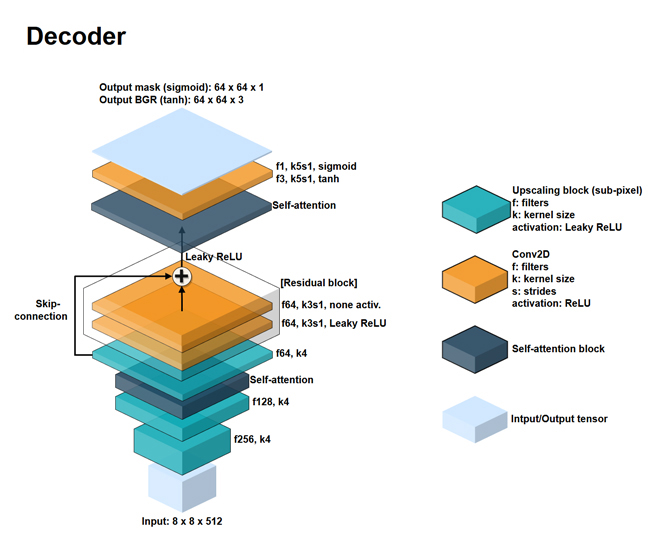
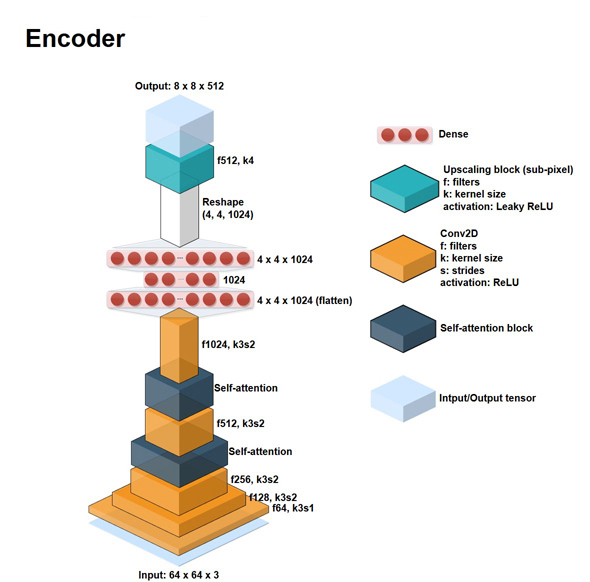
Aquí anexo el GitHub del que por poco me ahorraba la tarea de hacer una imagen para la arquitectura de deepfakes: FaceSwap-GAN.
Sin datos no hay paraíso
Todo parece ir perfectamente bien. Tenemos una implementación, tenemos la teoría detrás de nosotros que nos permite entender el código, la arquitectura de la red, ya deberíamos poder poner manos al asunto. ¿Qué podría faltar en este mar de posibilidades? Como bien mencioné antes, esta red neuronal funciona perfectamente cuando tienes una cara A y otra cara B y haces el entrenamiento. Al final solo le pones la cara de A a la cara de B y listo. Pero literalmente es SOLAMENTE ESO. No puedo ponerle la cara de B a la cara de A. No puedo poner ni la cara de A a la cara de otro C, ni la de B a C. Y, sin embargo, requiero muchos datos para hacer sólo ese aprendizaje. Bueno, pues hagamos que valga la pena. Por democracia se escogieron los dos sujetos con los que realizaremos el aprendizaje: el sujeto A es un estudiante de la clase (a.k.a el tuercas) y el sujeto B es el presidente de México (a.k.a AMLO). Aclaro que respeto a ambas figuras y nada de lo que resulte de aquí es con el afán de ofender ni de burlarse. Todo es por la experimentación y descubrir.
Nótese que vamos a hacer que la cara del sujeto A aparezca en los escenarios del sujeto B.
Parece que será pan comido conseguir suficientes datos para realizar el reconocimiento del sujeto B, ya que es una figura pública. Sin embargo, el estudiante A aún no es lo suficientemente famoso como para poder conseguir imágenes hechas por paparazzis, mostrando cada ángulo de él. Es por esto, que vamos a utilizar PreProcessing de keras para aumentar el número de datos de la siguiente manera:
amlo_path = 'fs/amlo/pruebas/'
gen = ImageDataGenerator(rotation_range=10, width_shift_range=0.1, height_shift_range=0.1, shear_range=0.15,
zoom_range=0.1, channel_shift_range=10, horizontal_flip=True)
def plots(n_foto, ims, figsize=(12,6), rows=1, interp=False, titles=None):
if type(ims[0]) is np.ndarray:
ims = np.array(ims).astype(np.uint8)
if (ims.shape[-1] != 3):
ims = ims.transpose((0,2,3,1))
f = plt.figure(figsize=figsize)
for i in range(len(ims)):
plt.setp(f.gca().get_xticklabels(), visible=False)
plt.setp(f.gca().get_yticklabels(), visible=False)
plt.imshow(ims[i], interpolation=None if interp else 'none')
plt.savefig(amlo_path + str(n_foto) + '_' + str(i) + '.jpg')Y así es como va quedando:
 Para más detalles, vean la libreta preprocesamiento en mi repositorio (esto no es parte de deepfakes, es original).
Para más detalles, vean la libreta preprocesamiento en mi repositorio (esto no es parte de deepfakes, es original).
Claramente esto se hizo para el sujeto A, ya que casi no tenemos fotos de él. No anexo sus fotos por privacidad.
¡Tengo un modelo pre-entrenado! Oh, espera…
Sí, es posible que te encuentres con un modelo pre-entrenado, que sería el de Nicolass Cage siendo A, y Donald Trump siendo B. Sin embargo, lo único que puedes hacer con ese modelo es volver a ponerle la cara de Nicolas Cage a Donald Trump. Por lo tanto, vamos a requerir hacer el entrenamiento nuevamente con nuestros propios datos. Para esto, el repositorio original (no oficial) te permite hacerlo sencillamente. El entrenamiento duró aproximadamente 72 horas, con un millón de epochs, en una GPU Titan V. Estos son algunos de los resultados:
 |
 |
|---|---|
 |
 |
 |
 |
Quiero hacer lo mismo con videos. ¿Es complicado?
Les adelanto la respuesta a la pregunta anterior: no. Un video no es más que una serie de imágenes. Para poder hacer que el tuercas diera la mañanera, realicé lo siguiente:
- Busqué un video de AMLO dando una mañanera.
- Bajé el video directamente desde Youtube (este mero)
- Le recorté con FFMPEG las partes donde aparecerían caras de otras personas para evitar conflictos.
- En 18 FPS, hice un ffmpeg para obtener todos los frames.
- Obtenidos todos esos frames (18 mil frames a partir del video recortado de un minuto) hice la conversión con la red neuronal ya entrenada.
- Estos nuevos 18 mil frames convertidos, los pasé a video, usando nuevamente ffmpeg.
Y, !vualá!. Ya podemos dar la mañanera.
Experimento 1: Mismo modelo pre-entrenado de el tuercas y AMLO.
¿Cuál es el problema con mis datos? ¿Se requiere todavía más preprocesamiento del que se hizo? La verdad es que sí. A pesar de tener más de 4,000 imágenes de AMLO y 3,000 de el tuercas (después del augmentationData que hicimos) hay algo que evita que sea lo mejor posible: ¡las resoluciones difieren demasiado! Mientras las fotos del tuercas fueron tomadas con lo que había a la mano (una cámara de teléfono, alguna cámara frontal, un buen zoom, un microondas, etc), las fotografías de AMLO son tomadas por profesionales, que si no las entregan a su trabajo en calidad y forma podrían ser despedidos. Esto causa una abismal diferencia y un problema que tendremos que ver como vamos a resolver. Sólo con el primer preprocesamiento de imágenes se obtuvo lo siguiente:

No está tan mal, pero seguro podría mejorar.
Experimento 2: mismo modelo de entrenamiento, diferentes datos de Swap.
Vamos a tratar de arreglar el problema empezando por lo menos costoso: vamos a reducir la calidad de las imágenes de AMLO a un nivel comparable al que tenemos con las del tuercas.
| Experimento 1 | Experimento 2 |
|---|---|
|
 |
Realmente no se notó mucha diferencia. Creo que la respuesta está en hacer un nuevo entrenamiento con los datos en baja calidad de AMLO y los de el tuercas.
Experimento 3: Nuevo modelo, con las mismas personas, pero con menos imágenes de AMLO. Para probar: los datos, ¿cantidad, o calidad?
En este experimento vamos a tener dos conjuntos de datos para entrenar: el de el tuercas será el mismo que en el anterior. Mientras que para AMLO serán algunas imágenes a las cuales pudimos reducir su calidad. Son menos datos, pero ahora podemos decir si efectivamente la calidad de las imágenes es substancial en el tratamiento de datos. El resultado fue el siguiente:

¡No parece funcionar así!
Hay algún factor que no se ha considerado aún, que es el de la iluminación. Si vamos a probar con un conjunto con poca iluminación, ambos datos deben contener imágenes de ambos sujetos con poca iluminación, y lo análogo a cuando hay mucha iluminación. De esto, podemos constatar, que la cantidad de datos es más importante que la calidad de imagen con la que llegan. En el siguiente experimento, notaremos cómo fue que la iluminación fue el único factor que no consideramos. Aún así, los movimientos se realizan de forma muy adecuada debido a la cantidad de datos con la que se entrenó.
Experimento 4: Nuevo modelo, nuevos datos
A continuación vamos a tratar de entrenar un nuevo modelo con POCOS datos, pero con una resolución muy similar entre las dos cámaras. Para ello, vamos a grabar dos videos: uno del sujeto A (ya no es el tuercas) y otro de un sujeto B (tampoco es AMLO). A partir de estos dos videos, donde ambos tratan de hacer expresiones variadas, se realizará el entrenamiento. Eventualmente, se hará la conversión. Aquí pueden ver el resultado.

Como pueden observar, debido a que no consideramos la ILUMINACIÓN como un posible factor de gran impacto en nuestros datos, el resultado no fue lo que esperábamos. En el experimento 5 notaremos cómo es que el simple hecho de tener datos con la misma iluminación afecta la conversión de gran manera.
Experimento 5: Nuevo modelo, nuevos datos, ahora con la misma luz.
| Experimento 4 | Experimento 5 |
|---|---|
|
 |
¡El pre-tratamiento de los datos es siempre de lo más importante! Conseguirlos, adaptarlos, formatearlos, multiplicarlos, entre muchas otras cosas, fueron tareas que se realizaron para hacer muchos más de estos cinco experimentos planteados aquí.
Mis conclusiones…
Traté de hacer lo que no debía, es decir, poner la cara del sujeto A en la cara de otro sujeto C. Gracias a los resultados que obtuve, me di cuenta que hay que tener en consideración algunas cosas importantes:
-
Los datos que obtengas de ambos sujetos deben estar a una calidad similar. Esta es una explicación a los resultados que tuve de poner la cara del sujeto A a otras personas, que veremos a continuación.
-
La iluminación es importante. Es por esto que muchas de las caras de AMLO salen más blancas de lo que deberían, ya que las fotografías del sujeto A usualmente es con mucha luz (además es blanco como la leche) y las de AMLO son fotos que le toman en alta calidad y reflejan la iluminación del momento muy adecuadamente.
Aquí las imágenes de poner la cara del sujeto A en otros sujetos C y D.


Sin duda fue una grata experiencia todo. Desde entender cómo funciona FaceSwap con deepfakes, la recopilación de datos, la evolución del entrenamiento (contando los epochs todas las mañanas), y sobre todo, el ver los resultados y cambiar la cara de mis amigos (literalmente). Gracias por leerme. Víctor Noriega.
