1. Introducción.
Primero lo primero, ¿Un ChatBot? ¿Porqué hacer un Chatbot, si ya hay muchísimos como CleverBot? Efectivamente. No hace falta buscar durante horas para encontrar docenas de bot en internet, ya implementados o en desarrollo. Incluso aplicaciones parecidas a Siri de Apple utiliza mecanismos internos parecidos a los de un ChatBot, pero además implementa un modelo acústico para hacer el reconocimiento de voz (mismo del que habló en otro blog). Sin embargo, la gran mayoría de estos está implementado en otros lenguajes. Incluso de una manera muy general, donde el desarrollo de uno hace parecer imposible o muy compleja la implementación de uno propio. Es por ello que propongo hacer un ChatBot más particular y familiar.
Bueno y, ¿cómo piensas hacer eso?
Con familiar me refiero a hacer un bot que se comunique de una manera mucho más coloquial. Para ello utilizaremos conversaciones de chats reales. Muy reales. Lo que hice fue pedirle a practicamente la mitad de todos los estudiantes de la Licenciatura en Ciencias de la Computación, incluso algunos egresados, que entablaran conversaciones del tipo que quisieran en un grupo de una red social. ¿Qué fue lo que resultó? Conversaciones mexicanizadas (la forma agradable de decir grosero, pero no hay problema). Después tomaré los datos obtenidos de las conversaciones, utilizaré expresiones regulares para hacer la limpieza de las conversaciones y le daré el formato que mejor convenga o que se adapte a algúno que exista para usar redes neuronales recurrentes.
 Imagen tomada de Wikipedia.
Imagen tomada de Wikipedia.
¿Por qué usar redes neuronales? ¿Nos hablarás de estas?
Porque son el estado del arte en muchas de las tareas y aplicaciones del procesamiento del lenguaje natural (como los chatbots); y sí, es lo principal de este blog: el hablar de las redes neuronales recurrentes, platicar un poco acerca de la arquitectura que se usa y debatir los resultados de experimentar con distintas capas (como las de atención) y cómo hacer para aprovechar las redes neuronales para resolver problemas en la aplicación (como por ejemplo, ¿porqué algunos chatbots, al hacer un mismo comentario, te responde siempre lo mismo?). Es posible que también hablemos de temás un poco específicos del procesamiento del lenguaje natural, pero solo aquellos que se vean afectados por el funcionamiento de la red neuronal.
2. ¡Los datos!

A diferencia de Mark Zuckerberg, yo nunca tengo los datos que necesito para empezar un nuevo proyecto (la ventaja de esto es que no tengo problemas de filtración de datos 😘) y tengo que conseguirlos por mi cuenta. Como mencioné en la sección anterior, los datos los estamos generando a través de conversaciones lo más naturales posibles. En un primer experimento, decidí utilizar los datos obtenidos en alrededor de 14 horas con menos de treinta personas participando en un chat. Son muy pocos datos, sí. Hay poco tiempo para entrenar, sí. Pero aún así, vale la pena echar un vistazo siempre, ¿no?
¡Oh, sorpresa! Los datos están más sucios que el bot marrano que planeamos hacer. Está lleno de media not available, Pingy was added, y Segundo 4 sent a sticker, además de que no nos interesa el nombre del que envía, la fecha, entre muchos otros detalles.
Vaya, qué pereza hacer la limpieza…
Pues no amigos. Los tiempos modernos nos permiten automatizar estas tareas. Te lo explico. Checa con atención la siguiente imagen:
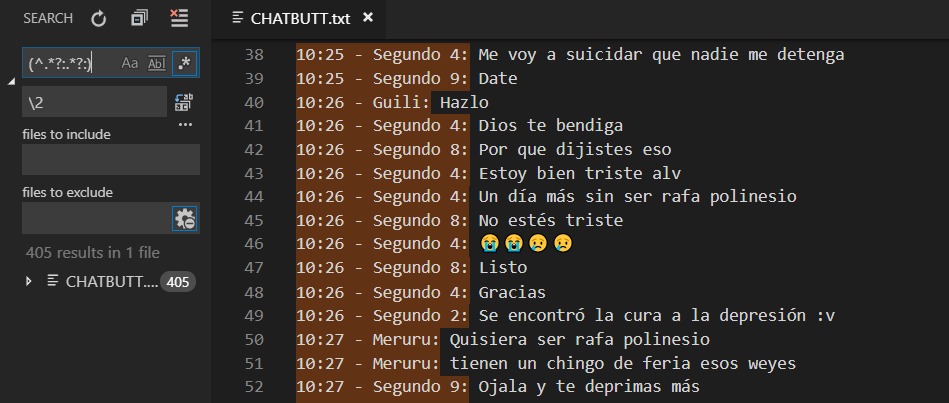
En el IDE Visual Studio Code podemos reemplazar ciertas partes del documento por otras utilizando expresiones regulares. El siguiente comando
(^.*?:/.?: )(.) Es para separar en dos grupos todo el texto: El primero es lo que quiero quitar, mientras el segundo es lo que vamos a dejar.
¿Cómo funciona?
- ^ indica inicio de línea
- .* es también llamado WildCard. Se utiliza para decir “ninguna o más veces cualquier caracter” en todo el texto.
- ?: es un indicador de que en la expresión debe aparecer tan solo una vez el símbolo de dos puntos :
Nótese que con esto podemos limpiar eficientemente todo el texto que no querramos utilizar. Lo similar se usó para limpiar los textos de media not available, ya que aún no implementamos un bot que responda con imágenes.
Oye, ahí vi emojis, ¿no hay problema?
Siempre y cuando codifiquemos con UTF-8 o similares no debería de darnos problemas, aunque en consola es muy probable que algunas veces no nos aparezca. Incluso hay emojis que el navegador aún no soporta.

3. La red neuronal
El desarrollo e implementación de muchos de los ChatBots de hoy en día involucra utilizar redes neuronales para determinar cuál es la mejor respuesta a una oración dada. Para esto es que usamos los datos de los que hablé hace un momento. En general, la arquitectura de la red puede ser vista como una Seq2Seq, es decir, a partir de una secuencia mapea otra secuencia. El artículo en el que se basó la implementación original es esta, el cual es conocido como el bot de Google, donde explican que la función a optimizar es la entropía y que por supuesto el aprendizaje es hecho con backpropagation o B-prop. En la implementación en Tensorflow que hicieron hace casi 2 años, esta, el optimizador que utilizan es Adam, el número de capas recurrentes tipo LSTM es 2 por default. Nosotros averiguaremos en experimentos siguientes qué ocurre cuando metemos más capas recurrentes. El número de unidades ocultas por cada neurona RNN es de 512 por defecto, pero también jugaremos con este parámetro; otros parámetros de entrenamiento que mantendremos son el dropout de 0.9, el tamaño de minibatch es de 256, y el tamaño del vector codificado por palabra es de 64. Aquí podemos ver un paper (en el que se basó el anterior) en el cual muestran cómo se implementó la arquitectura de una RNR Seq2Seq. Explican el cómo y el porqué usan una arquitectura tipo Auto-Encoder (puedes ver más de Auto-Encoders en mi otro blog), pues codifican la secuencia de entrada a un vector de dimensionalidad fija, y luego ese vector de dimensionalidad fija lo decodifican en otra secuencia de salida (que es la respuesta del bot). Aunque en ese último paper el objetivo es hacer traducciones, la arquitectura general de la red es muy versátil y flexible que permite utilizarlo para más cosas que solo traducir y hacer chatbots.
| Codificador | Decodificador |
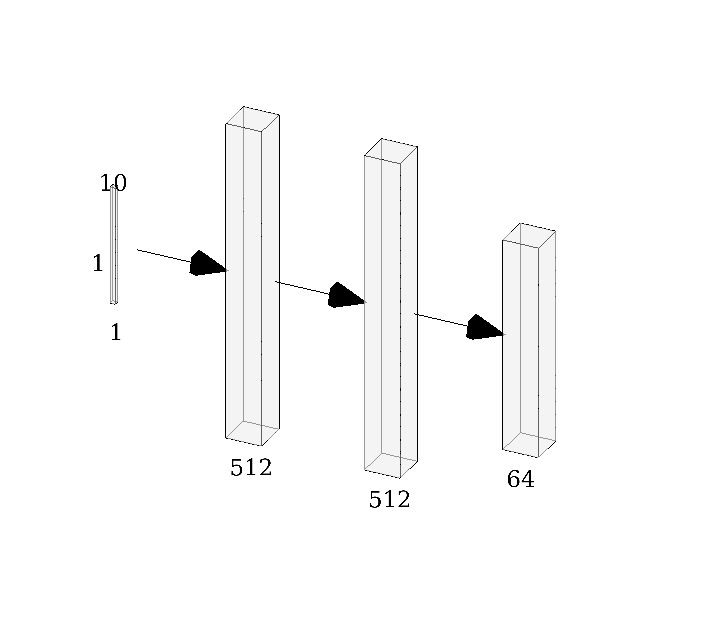 |
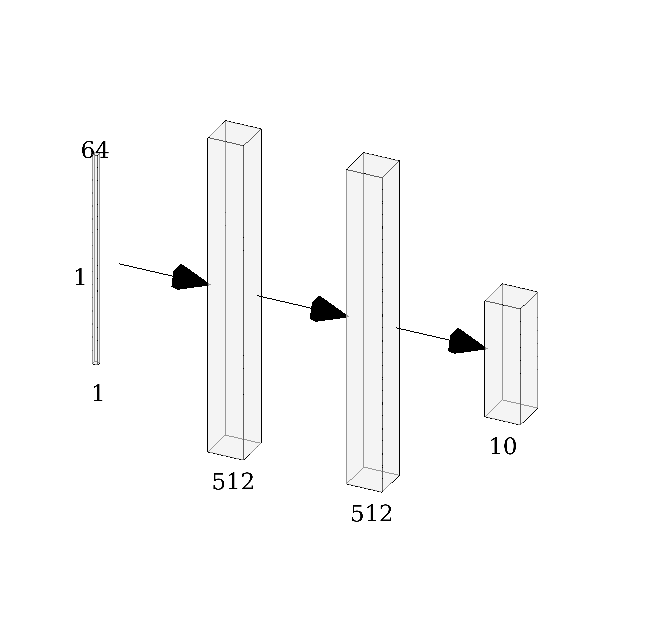 |
Extra: Tensorboard para controlar sobreaprendizaje.
¿Cuántos epochs es lo correcto entrenar? ¿Cuándo sabemos que ya nos pasamos? ¿Cuánto nos falta? Es claro que la función de costo es un indicador clave para determinarlo. Sin embargo, es difícil de monitorear a partir de las salidas en consola, pues tendríamos que checar todo el historial en una tabla. Otra alternativa: graficar el costo en función de los epochs, pasos o tiempo. Para esto ya existe una herramienta fácil de usar, la cual es tensorboard. Esta herramienta permite saber cuando es momento de decir ay’ estuvo de manera rápida y amigable. Aquí pongo dos ejemplos de algunos modelos:
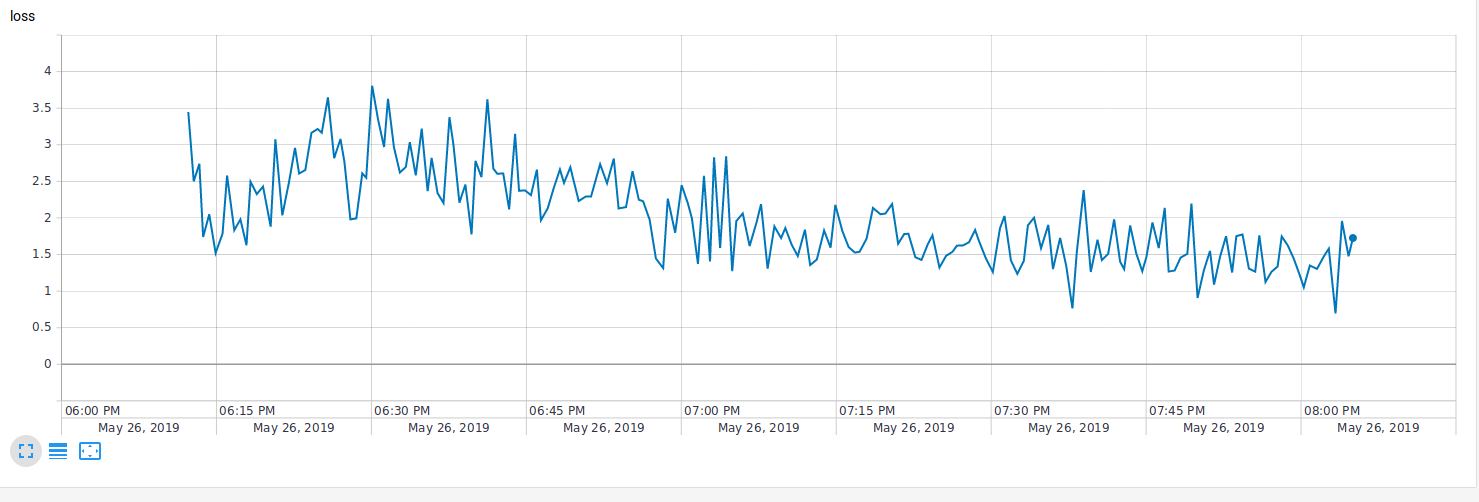 |
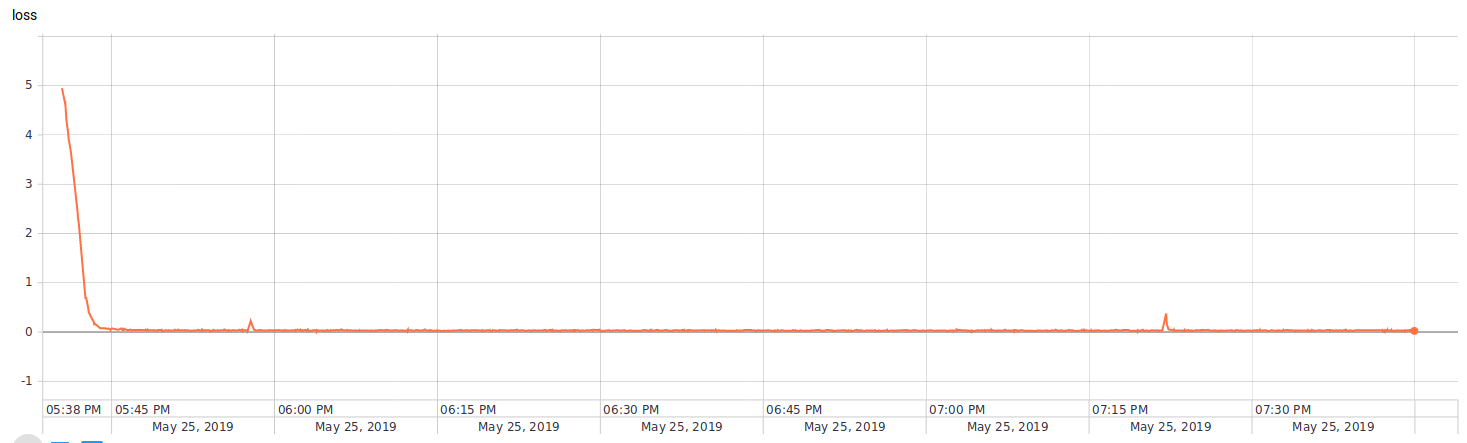 |
4. Experimentos.
Estos son algunos de los experimentos que me propuse a realizar:
- Conseguir un conjunto de datos original (del que hablamos en la sección 2) pequeño, y tratar de compararlo con uno más grande. Ambos con un entrenamiento de unos 10,000 epochs.
- Con el mismo conjunto de datos, probar la función SampledSoftmax y comparar resultados con el anterior.
- Usando SampledSoftmax, utilizar o agregar capas de atención en el modelo de la red.
- A partir de la misma arquitectura y el mismo modelo, hacer un tuneo de los hiperparámetros de la red. Es posible también agregar más capas profundas aquí, y cambiar la longitud del vector que representa cada palabra (de 64 a 128).
4.1. Pocos datos, resultados muy buenos.
En este primer experimento, vamos a utilizar la arquitectura por defecto de la implementación original y hacer dos pruebas: una con los datos que se recaben en un día, y otra con los datos recabados en cinco días.
Estos son algunos de los resultados obtenidos:
| Datos | Día 1 | Día 5 |
| Palabras | 637 | 1310 |
| Conversaciones | 505 | 932 |
| Epochs | 10,000 | 10,000 |
| Resultado 1 |  |
 |
| Resultado 2 |  |
 |
La conversación que puede mantener el bot crece muchísimo, además de que tiene más sentido a lo que se está diciendo o preguntando. Claro que podríamos todavía mejorar los resultados con un poco más de datos, pero se vuelve muy complicado obtener datos de este estilo.
4.2. Un bot más atento
En la introducción de esta experimentación se mencionó que íbamos a agregar una capa de atención. Últimamente (desde mediados del 2018) se ha mostrado un gran avance en la implementación de la capa de atención en las redes LSTM. He aquí el resultado
| Bot sin atención | Bot atento |
 |
 |
Yo creo que ambos resultados están buenos. Vale la pena seguir explorando la capa de atención.
4.3 Tuneando la red
Vamos a moverle más a la red. Para ello, decidimos agregar dos capas LSTM más al modelo con 1024 unidades. Creo que este fue el resultado más gracioso.

En general, parece que todos los modelos dieron muy buenos y divertidos resultados. En una siguiente versión, prometo que el bot podrá hablar un español más rico que no solo consista en groserías (ya que si le hablamos de otra cosa no lo entenderá). Gracias.
