
1. Introducción
En el aprendizaje por refuerzo, a diferencia de los otros tipos de aprendizaje automático, buscamos conocer una política , donde es un conjunto de estados, es el conjunto de acciones que tiene el agente. En este tipo de aprendizaje, destacan dos cosas: hay un entorno que es el que sufre cambios debido al agente, y éste último realiza las acciones que modifican su propio entorno. Aún así, la característica principal que distingue al aprendizaje por refuerzo es que evalúa las acciones que ya fueron tomadas, en vez de instruir dando las acciones correctas, lo cual es algo que personalmente me parece muy atractivo y fascinante, ya que se apega mucho más al aprendizaje humano, y el encontrar relación con el aprendizaje automático y el humano debería ser más tomado en cuenta (como antes). Pero en este blog no venimos a hablar de esto. En este blog hablaremos de un algoritmo en particular y su implementación, DeepQL, Deep-Q-Learning, etcétera, y algunas de sus modificaciones que ha sufrido por el camino con el fin de dar mejores resultados, en particular, hablaremos de un algoritmo basado en DQN gracias al cual muchos de los juegos probados con DQN (como el Zaxxon 2600 Atari) parecían no funcionar con éste último, gracias a la modificación hecha dio resultados que mostraban una inteligencia artificial jugando a nivel super-humano al Zaxxon.
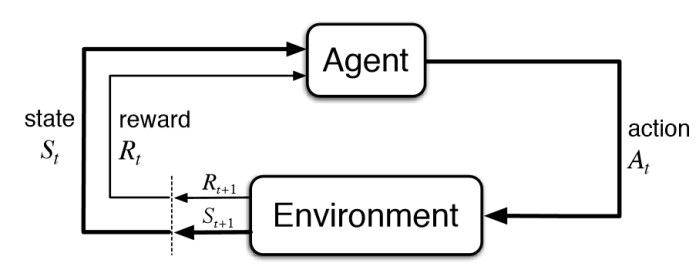
Imagen tomada del libro de Sutton (referenciado más abajito)
2. Familiarizándonos con el aprendizaje por refuerzo.
En el aprendizaje por refuerzo, buscamos maximizar , la cual es la esperanza de una secuencia de recompensas que regresa nuestro entorno. Para ello, el agente toma decisiones, observa su nuevo entorno y recibe una recompensa, donde a partir de estas últimas dos (entre otras cosas) aprende, con el fin de maximizar . Los Procesos de decisión markoviana, o MDP, nos permiten formalizar esa secuencia de recompensas, haciendo que el agente no solamente actúe buscando la mayor recompensa en corto tiempo, sino también a largo plazo. El hecho de que un agente busque maximizar su recompensa a corto plazo es llamado explotación, mientras que, cuando no toma decisiones basado en ello, se le llama exploración. En la práctica, usualmente se busca con una probabilidad de que el agente busque explorar, a esto se le llama un agente -greedy, los cuales son muy, muy comunes.
Casi todos los algoritmos de aprendizaje por refuerzo tienen estimadores en forma de funciones que indican qué tan bueno es estar donde estamos y hay de dos sopas:
- Funciones de valor
- Funciones de acción-valor
La función de valor de un estado bajo la política se denota como y es el valor esperado de dado el estado . Como una ecuación vale más que mil imágenes:
donde es un instante en el tiempo. Como lo habrán pensado, la función de acción-valor es lo análogo, pero ahora considerando que ya se tomó alguna acción .
Existen métodos en el aprendizaje por refuerzo los cuales pueden aprender directamente desde la experiencia sin un modelo explícito del entorno (como los Métodos de MonteCarlo); también existen otros donde actualizan sus estimaciones sin tener que esperar que el entorno regrese algo, sino en otros estimados aprendidos (como la Programación dinámica); una muy buena idea de la combinación de estos dos, son las diferencias temporales.
Debido a la siempre-existente necesidad de encontrar el balance entre la exploración y la explotación, existe una bifurcación que separa nuestro acercamiento en dos clases: On-policy y Off-policy: el acercamiento On-policy consta de tomar una acción, observar el nuevo estado y recibir la recompoensa, y aprender actualizando nuestra función de acción valor evaluado en el estado actual (es decir, ) a partir de la función de acción-valor del nuevo estado (, donde es el nuevo estado al que llegamos por tomar la acción en el estado y la obtenemos siguiendo la política en el estado . ).
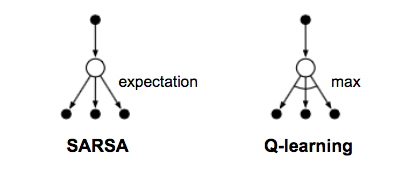
Off-policy es una versión más greedy: aprende actualizando a partir de la función de acción-valor con la acción que nos maximiza , en vez de la que usa On-policy. En las diferencias temporales, existen dos algoritmos muy populares donde uno es On-policy (SARSA), y el otro es Off-policy (Q-Learning, el importante para este blog). Aquí adjunto algunas referencias muy serias acerca del tema para poder familiarizarse aún mejor en los temas que vamos a tratar:
- Libro de Sutton para aprendizaje por refuerzo (la biblia del RL aún sin terminar)
- Algoritmo Q Learning (Watkins, 1989, no está disponible en línea).
- Algoritmo Double-Q Learning (van Hasselt)
- Primer paper de Deep Q Networks’ (DQN, 2013), con capas convolucionales
- DQN con Double-Q learning
- Bootstrapped Double-DeepQ-Learning (2016)
3. Conociendo el estado del arte en RL
Ya conocemos (en alto nivel por lo menos) a QLearning, el cual aprende una política Off-policy a partir de una función de acción-valor. Sin embargo, por lo que vimos en las referencias anteriores, no todo quedó ahí.
Podemos ver Q-learning como un medio para utilizar un estimador del valor del siguiente estado (arg. que maximiza Q), que al mismo tiempo aproxima o estima el valor esperado , lo cual puede verse como un promedio de todas las corridas del mismo experimento y no acerca del siguiente estado, por lo que Q-learning podría sobre-estimar Q. Para solucionar esto, se propuso Double Q-learning, la cual utiliza no solo una función acción valor, sino dos, , y cada una es actualizada en función de la otra para el siguiente estado.
Tampoco esto se quedó ahí. Poco tiempo después aparecieron las DQN, las cuales replantean la función Q, de ser , a ser , donde es un conjunto de parámetros obtenidos de una red neuronal, las cuales aprenden a partir de lo que están viendo, es decir, a partir de la imagen actual de su entorno toman decisiones. Para esto, es muy común utilizar redes neuronales convolucionales (aquí hice un blog donde explico y las aplico a un problema real) las cuales forman parte del estado-del-arte en cuanto a procesamiento de imágenes automático.
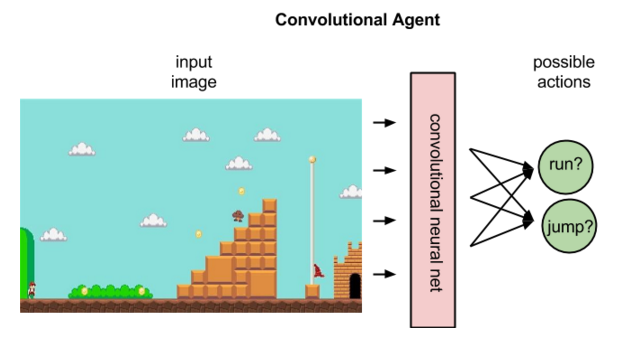
DQN utiliza la imagen actual del juego como entrada para su red neuronal convolucional.
DQN es una generalización a todos los algoritmos de aprendizaje por refuerzo que utilicen redes neuronales para estimar sus parámetros. Entre estos algoritmos están Deep Q-learning, Double-Deep Q-learning, y Bootstrapped Double-Deep Q-learning, los cuales son el foco de este blog.
3.1 Cómo funciona Bootstrapped Q-learning
Primero que nada, ¿a qué le llamamos Bootstrap en RL? En diferencias temporales o TD, solemos ver ecuaciones como estas
Donde es un estimado al valor real de , es decir que estamos tratando de actualizar nuestra función Q a partir de nuestra función , a diferencia de los métodos de Montecarlo, que podríamos ver la actualización de la función de valor de esta manera:
Donde no es un estimador de Q, sino que es el regreso del entorno en el instante , el cual es el estado final de un episodio y que notablemente no actualiza por cada transición.
En BDQN, al inicio de cada episodio se muestrea una función a partir de su aproximado a posteriori. El agente debe seguir la política la cual es óptima para esa muestra durante el episodio. Es como una versión más paralelizable del DQN, a su vez que da mejores resultados con K = 10, donde K es el número de muestras por episodio.
4. Conociendo la implementación de RL
Mientras investigaba y leía acerca del Framework más popular para hacer RL, OpenAI: Gym, me di cuenta que, si bien es una herramienta muy poderosa con muchos algoritmos implementados, aún carecía de algunas cosas importantes en la actualidad. Dentro de OpenAI Gym, hay algo maravilloso que se llama entorno, que facilitan el utilizar modelos neuronales convolucionales al implementar una interfaz entre los emuladores de los juegos de ATARI, SEGA, NES, etc, y un agente de aprendizaje por refuerzo. De hecho, gran parte de los frameworks populares utilizan estos entornos de OpenAI Gym para hacer tus pruebas o incluso los entrenamientos. Una vez eché un vistazo noté otros dos proyectos interesantes: OpenAI: Retro el cual busca hacer lo mismo que OpenAI: Gym, pero con algunos juegos de plataformas más modernas (en comparación con la ATARI 2600) como de SNES, N64, Genesis, etcétera; y OpenAI: Baselines el cual provee algoritmos muy buenos para realizar el entrenamiento.
Para comenzar a hacer algunas deliciosas y exquisitas pruebas, comencé por elegir un juego Zaxxon ATARI 2600. Algunas de las razones por las cuales lo elegí fueron:
- Es un juego muy complicado para el humano.
- Es un juego muy complicado para RL (pocos algoritmos superan al humano).
- La parte visual es realmente muy confusa, por lo que pienso que es un punto débil del actual RL.
Por lo que traté de entrenar utilizando Deep Q-learning vainilla, sin embargo, los resultados fueron pésimos, así que empecé a buscar nuevas opciones sin tener que recurrir a cambiar el juego.
Algunos de los entornos que ofrece OpenAI Gym
Papers with code: uma delicia.
Papers with code es una plataforma que, en general, trata de recopilar papers en el estado del arte, y algunas de sus implementaciones más populares y utilizadas. En particular, para los juegos de ATARI, nos muestra una lista de qué algoritmos han obtenido la mayor puntuación para cada juego. Esto es grandioso ya que gracias a esto conocí algoritmos y adaptaciones interesantes, como justamente Bootstrapped DQN, tuve acceso a la referencia de papers en el estado del arte, y conocí frameworks de los que pronto hablaré.
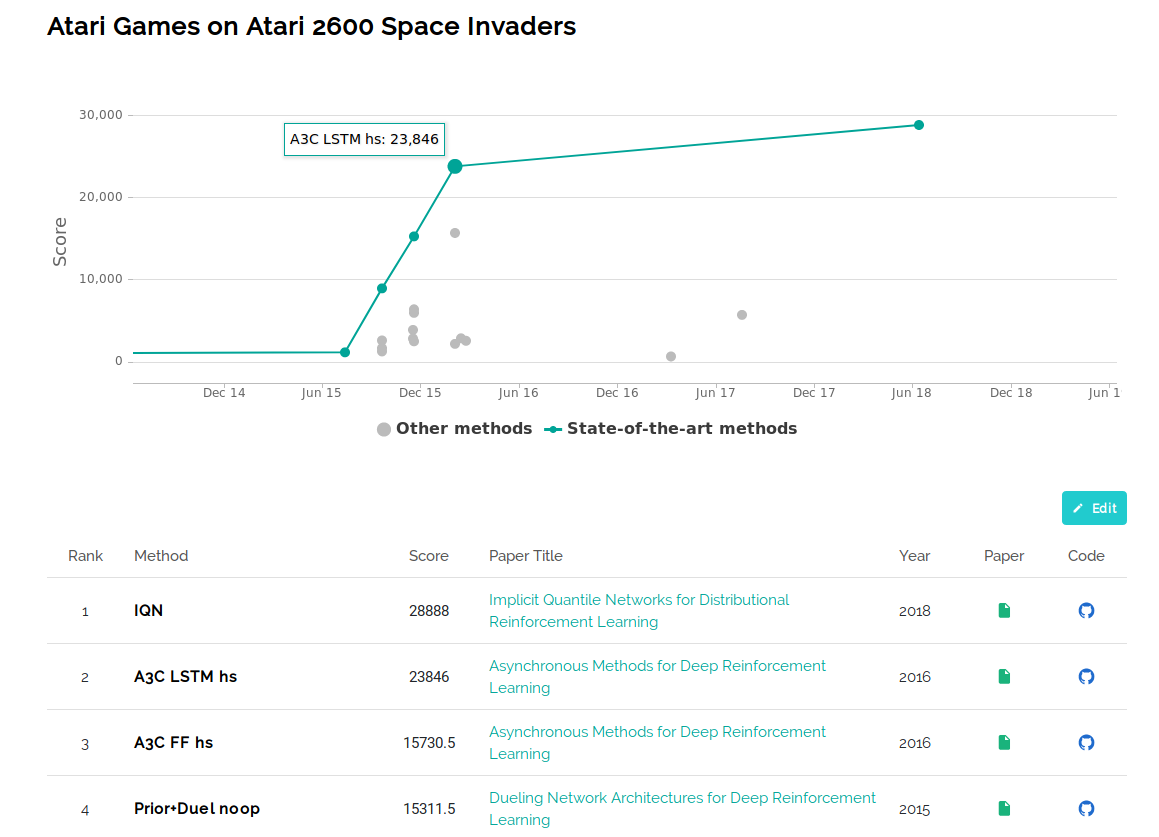
Los mejores algoritmos para Space Invaders, con sus Scores, los papers y el código.
Frameworks para hacer RL
Si bien Gym es el framework quizá más conocido ya que formó una base de entornos para juegos que utilizan todos, no es el único. También Tensorflow cuenta con sus propios algoritmos implementados para realizar RL. Sin embargo, uno se ganó mi confianza por tener implementados los algoritmos más novedosos y nuevos es Coach, el cual es mantenido como producto no-oficial de Intel. Es en realidad buenísimo: tiene algo llamado presets los cuales son entornos funcionando con algoritmos ya determinados. Cuentan con algoritmos que salieron incluso el año pasado (2018) y dan soporte a entornos No-Gym, como CARLA, Doom y Starcraft. Es importante la gran variedad de algoritmos, ya que gracias a esto fue que pudimos utilizar Bootstrapped Deep Q-learning, el 7mo mejor algoritmo para jugar Zaxxon.
Aquí dejo referencia a otro buen blog acerca de los Frameworks más populares en RL en Medium.

Algunos entornos de Coach, de Intel.
5. Resultados
Utilicé el framework de Coach ya que en Gym aún no está implementado Bootstrapped DDQN. Después de entrenar la red neuronal durante unas 6 horas en una GPU Tesla V100, con cerca de 1 millón de pasos, estos son los resultados obtenidos:
| Yo, un jugador pésimo de videojuegos no-estratégicos | Una máquina triunfante con 2600 puntos en Zaxxon |
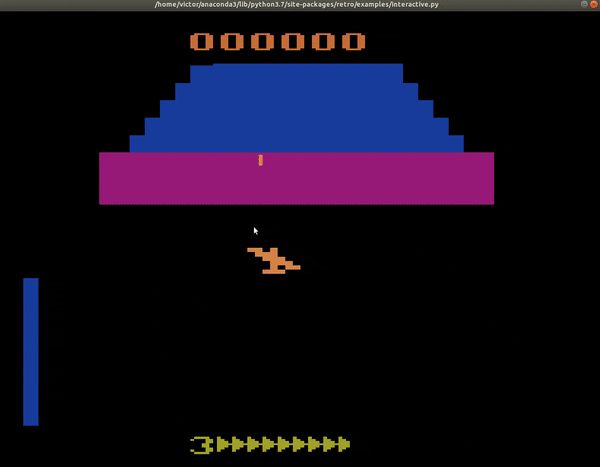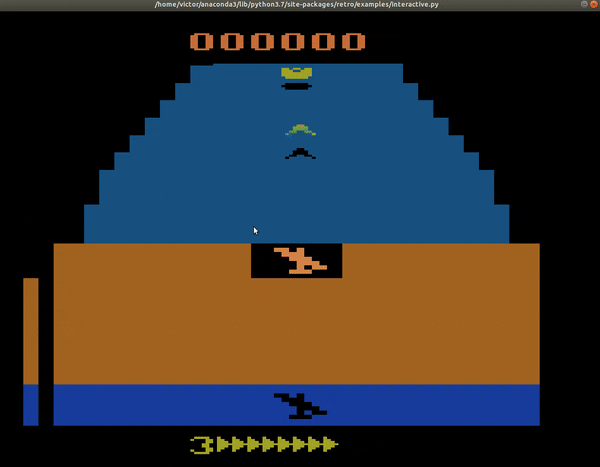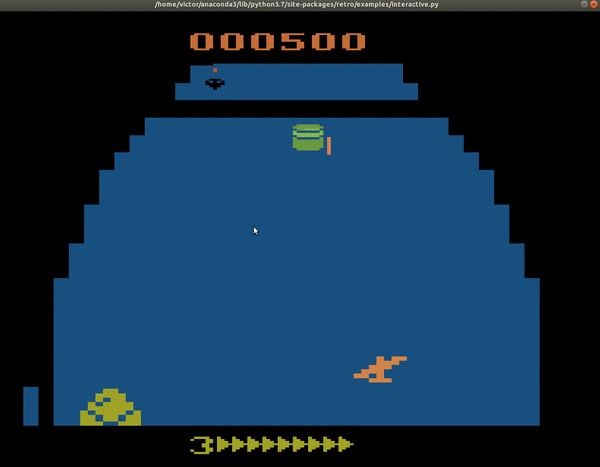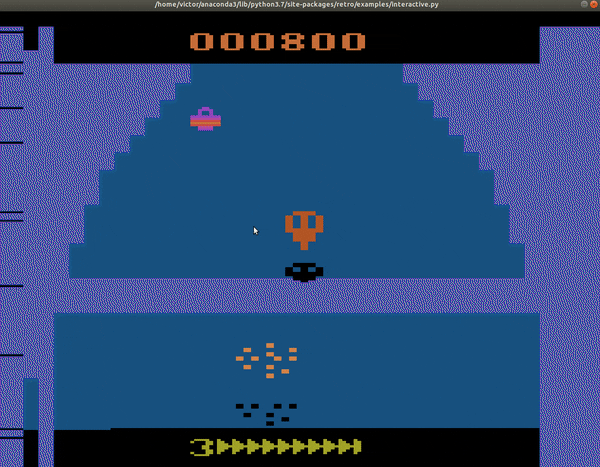 |
|
Como se puede ver en ese ejemplo, el entrenamiento del bot fue un éxito. Los estudios muestran que el número de pasos adecuados para casi todos los algoritmos es de alrededor de 40 millones. Estuvimos muy lejos de alcanzar eso por recursos limitados, sin embargo, de haberlo hecho, la IA podría alcanzar hasta más de 11,000 puntos en Zaxxon. El lograr estos resultados se logró gracias al dominio de distintas herramientas, el poder reconocer los hiperparámetros del Bootstrapped-DDQN y también gracias a que pudimos tunear los parámetros de la red convolucional. Gracias por leerme hasta aquí.
